Scraping Walmart to Estimate Share of Sugar in Food


Scraping Walmart to estimate share of sugar in food

In previous posts, we've already covered scraping publicly available data from Instagram and Airbnb. This time, we'll show you how to scrape walmart.com to collect data about products by category. Walmart is a rich source of data containing:
- product details (including category and description) 📝
- price 💰
- features (e.g. nutrition facts for food) 🥦
- availability 🛒
- reviews ⭐️
As always, we share the code in GitHub repository to let you play with it and apply to your use case. To be able to run it and actually scrape the data, you need Scraping Fish API key which you can get here: Scraping Fish Requests Packs. A starter pack of 1,000 API requests costs only $2. Without Scraping Fish API you are likely to see captcha instead of useful product information.
Scraping use case
As a 🏃♂️ running example, we'll identify products from 🍔 food categories and scrape nutrition facts data for them. Based on collected data for over 15,000 products, we'll find out:
- What is the share of products having sugar as the main nutrient?
- Is there any relation between product rating and its nutrients?
Go straight to Data Exploration if you want to skip technicalities related to web scraping Walmart and data collection.
Walmart categories
Walmart categories are represented by codes and have hierarchical structure. A list of all Walmart categories can be found in a sitemap file. At the time of writing this post (October 2022), there are two xml files there which we can download to extract category codes from them.
Depending on your needs, you can filter for sub-categories by code. The easiest way to identify a category code of interest is to go to walmart.com, find a representative product and then go to its category which is shown at the top, above the product images.
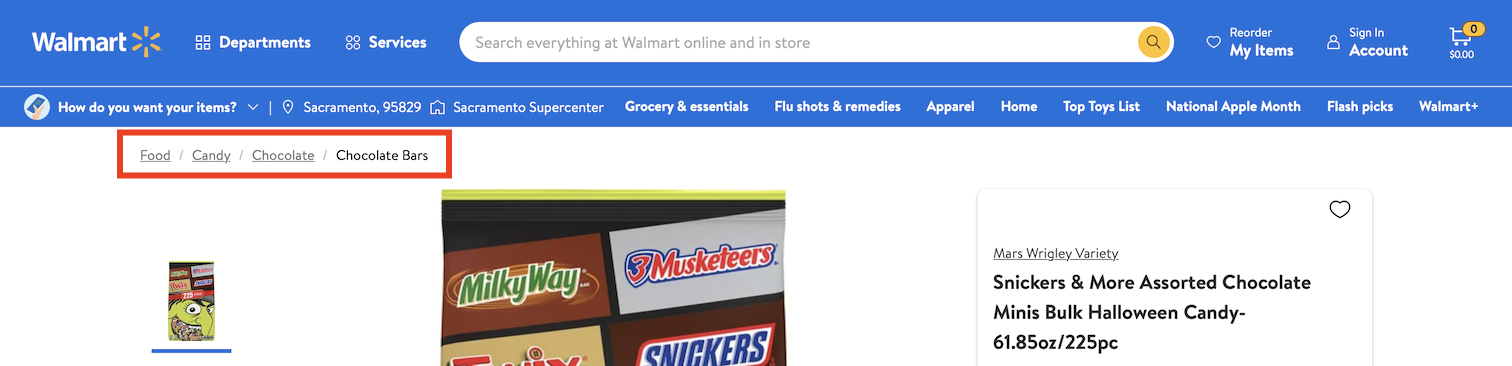
For the "Chocolate Bars" category, it redirects to URL
https://www.walmart.com/browse/chocolate/chocolate-bars/976759_1096070_1224976_3761246
From this we can infer the following categories for codes:
- 976759: Food 🍔
- 1096070: Candy 🍭
- 1224976: Chocolate 🍫
- 3761246: Chocolate Bars
- 1224976: Chocolate 🍫
- 1096070: Candy 🍭
If we want to, for example, scrape products from Candy sub-categories, we have to filter for category codes from sitemap_browse_fst.xml which start with 976759_1096070.
This rule is applicable to any (sub)category.
In our example, we consider all lowest-level sub-categories in food category (starting with code 976759).
A list of category urls prepared to scrape products should look like this:
https://www.walmart.com/browse/976759_1086446_1100007_1447529
https://www.walmart.com/browse/976759_1086446_1100007_2301544
https://www.walmart.com/browse/976759_1086446_1100007_5381118
https://www.walmart.com/browse/976759_1086446_1100007_8460141
https://www.walmart.com/browse/976759_1086446_1100007_9155009
https://www.walmart.com/browse/976759_1086446_1229650
https://www.walmart.com/browse/976759_1086446_1229653
https://www.walmart.com/browse/976759_1086446_1229654_7128412
https://www.walmart.com/browse/976759_1086446_1229655_3951471
https://www.walmart.com/browse/976759_1086446_1371544_9455098
...
Python code to prepare category URLs
from xml.etree import ElementTree
selected_category = "976759" # Food
root = ElementTree.parse("sitemap_browse_fst.xml").getroot()
urls = set()
for url in root:
urls.add(url[0].text)
food_category_codes = set()
for url in urls:
category_code = url.split("/")[-2]
if category_code.startswith(selected_category):
food_category_codes.add(category_code)
final_food_category_codes = set()
for code in sorted(food_category_codes, key=len, reverse=True):
if not any([c.startswith(code) for c in final_food_category_codes]):
final_food_category_codes.add(code)
browse_urls = []
for code in sorted(final_food_category_codes):
browse_urls.append(f"https://www.walmart.com/browse/{code}")
with open("category_urls.txt", "w") as f:
f.write("\n".join(browse_urls))
Scraping product URLs
The next step is to scrape product URLs for all Walmart categories of interest. For this, we have to find product IDs in the container with results and handle pagination. Both tasks are fairly straightforward with the use of BeautifulSoup library in python.
The container with all products on the category page is the parent of container with id results-container.
Then, we extract link-identifier attribute value from link elements <a> and use it to construct the product details URL in the following format: https://www.walmart.com/ip/{product_identifier}, for example:
https://www.walmart.com/ip/555295433
For pagination, we simply have to check if the next page exists by looking for a link having aria-label attribute with value Next Page.
If there is no such element, we've reached the last page, otherwise we can open the next page by specifying it in the page query parameter, for example:
https://www.walmart.com/browse/976759_1086446_1100007_2301544?page=2
Python code to scrape product URLs
from typing import Optional
from urllib.parse import quote_plus
import pandas as pd
import requests
from bs4 import BeautifulSoup
from retry.api import retry_call
from tqdm import tqdm
API_KEY = "YOUR SCRAPING FISH API KEY" # https://scrapingfish.com/buy
url_prefix = f"https://api.scrapingfish.com/api/v1/?api_key={API_KEY}&url="
def request_html(url: str) -> Optional[str]:
response = requests.get(url, timeout=90)
if response.ok:
return response.content
if response.status_code == 404:
return None
response.raise_for_status()
with open("category_urls.txt", "r") as f:
category_urls = f.read().splitlines()
try:
df = pd.read_csv("product_urls.csv")
except:
df = pd.DataFrame({"category_code": [], "category_name": [], "product_url": []})
df.to_csv("product_urls.csv", index=False, mode="a")
with tqdm() as pbar:
for url in category_urls:
category_products = set()
category = ""
page = 0
while page < 100:
page = page + 1
browse_url = (
quote_plus(url + f"?page={page}&affinityOverride=default") if page > 1 else quote_plus(url + "/")
)
category_html = retry_call(request_html, fargs=[f"{url_prefix}{browse_url}"], tries=10)
if category_html is None:
print(f"\n404 for url {browse_url}")
break
soup = BeautifulSoup(category_html, "html.parser")
results_container = soup.find("div", {"id": "results-container"})
if results_container:
if page == 1:
category = results_container.find("h1").text
print(f"\n{category}")
page_products = set(
[
href.get("link-identifier")
for href in results_container.parent.find_all("a", {"link-identifier": True})
]
)
category_products = category_products.union(page_products)
pbar.update()
if len(soup.find_all("a", {"aria-label": "Next Page"})) == 0:
break
category_product_urls = [f"https://www.walmart.com/ip/{p}" for p in category_products]
df = pd.DataFrame(
{
"category_code": [url.split("/")[-1]] * len(category_products),
"category_name": [category] * len(category_products),
"product_url": category_product_urls,
}
)
df.to_csv("product_urls.csv", index=False, header=False, mode="a")
Product details JSON
Now that we have URLs for all the products we want to scrape, we download product page HTML using Scraping Fish API to obtain a JSON containing all available product details and save it locally.
Using BeautifulSoup we extract a script element with id __NEXT_DATA__ which contains the JSON we need.
Python code to scrape product details JSON
import json
from pathlib import Path
from typing import Optional
from urllib.parse import quote_plus
import pandas as pd
import requests
from bs4 import BeautifulSoup
from joblib import Parallel, delayed
from retry.api import retry_call
API_KEY = "YOUR SCRAPING FISH API KEY" # https://scrapingfish.com/buy
url_prefix = f"https://api.scrapingfish.com/api/v1/?api_key={API_KEY}&url="
concurrency = 10
def request_html(url: str) -> Optional[str]:
response = requests.get(url, timeout=90)
if response.ok:
return response.content
if response.status_code == 404:
return None
response.raise_for_status()
df = pd.read_csv("product_urls.csv")
Path("./products/").mkdir(parents=True, exist_ok=True)
def scrape_product(url: str):
product_id = url.split("/")[-1]
if not product_id.isdigit():
print(f"Invalid product id {product_id}")
return
html = retry_call(request_html, fargs=[f"{url_prefix}{quote_plus(url)}"], tries=10)
if html is None:
print(f"404 for url {url}")
return
soup = BeautifulSoup(html, "html.parser")
json_element = soup.find("script", {"id": "__NEXT_DATA__"})
if json_element is None:
print(f"No json data for url {url}")
return
try:
page_json = json.loads(json_element.text)
except Exception as e:
print(f"Error for url {url}")
print(e)
return
data = page_json.get("props", {}).get("pageProps", {}).get("initialData", {}).get("data", {})
product_json = {"data": {k: data.get(k) for k in ["product", "idml", "reviews"]}}
product_id = url.split("/")[-1]
with open(f"./products/{product_id}.json", "w") as f:
json.dump(product_json, f)
Parallel(n_jobs=concurrency, verbose=1)(delayed(scrape_product)(url) for url in df["product_url"].unique())
Here is an example extracted JSON to give you an idea of what kind of data you can find there:
Product details JSON
{
"data": {
"product": {
"availabilityStatus": "IN_STOCK",
"averageRating": 4.7,
"brand": "Goldfish",
"brandUrl": "/c/brand/goldfish",
"badges": {
"flags": [
{
"__typename": "BaseBadge",
"id": "L1200",
"text": "Popular pick",
"key": "CUSTOMER_PICK",
"query": "goldfish colors",
"type": "LABEL"
}
],
"labels": null,
"tags": []
},
"rhPath": "40000:42000:42004:42107:42245",
"manufacturerProductId": "00014100096566",
"productTypeId": "191",
"model": "0001410009656",
"buyNowEligible": false,
"canonicalUrl": "/ip/Pepperidge-Farm-Goldfish-Crackers-Colors-Cheddar-30-oz-Carton/16940090",
"category": {
"categoryPathId": "0:976759:976787:1001392:1904919",
"path": [
{
"name": "Food",
"url": "/cp/976759"
},
{
"name": "Snacks, Cookies & Chips",
"url": "/cp/976787"
},
{
"name": "Crackers",
"url": "/cp/1001392"
},
{
"name": "Goldfish Crackers",
"url": "/cp/1904919"
}
]
},
"classType": "REGULAR",
"fulfillmentTitle": "title_shipToHome_oneday_delivery",
"shortDescription": "With Goldfish crackers, the smiles come naturally. Baked with 100% real cheddar cheese, plus no artificial flavors or preservatives, Goldfish Colors are a snack the whole family will adore. All colors are sourced from plants. The red Goldfish crackers are colored using a mix of beet juice concentrate and paprika extracted from sweet red peppers. Green comes from watermelon and huito juice concentrates mixed with extracted turmeric. The red-orange Goldfish are colored with paprika extracted from sweet red peppers, and finally, the orange Goldfish use annatto extracted from the seed of the achiote tree. With a large 30 oz. carton you can always come back for more, or have enough to feed a crowd. For Pepperidge Farm, baking is more than a job. It's a real passion. Each day, the Pepperidge Farm bakers take the time to make every cookie, pastry, cracker and loaf of bread the best way they know how by using carefully selected, quality ingredients.",
"fulfillmentBadge": "Tomorrow",
"fulfillmentLabel": [
{
"checkStoreAvailability": null,
"wPlusFulfillmentText": null,
"message": "Pickup, today at Sacramento Supercenter",
"shippingText": "Pickup",
"fulfillmentText": "today",
"locationText": "Sacramento Supercenter",
"fulfillmentMethod": "PICKUP",
"addressEligibility": false,
"fulfillmentType": "STORE",
"postalCode": null
},
{
"checkStoreAvailability": null,
"wPlusFulfillmentText": null,
"message": "Shipping, arrives by tomorrow to Sacramento, 95829",
"shippingText": "Shipping",
"fulfillmentText": "arrives by tomorrow",
"locationText": "Sacramento, 95829",
"fulfillmentMethod": "SHIPPING",
"addressEligibility": false,
"fulfillmentType": "FC",
"postalCode": "95829"
}
],
"id": "1K83G4N9GAM8",
"imageInfo": {
"allImages": [
{
"id": "87CED83E5BD14328A54C27ECF808A0D9",
"url": "https://i5.walmartimages.com/asr/b6e643cb-03ca-428f-9b74-5b23c3f9b993.ccedb091549bc1473c5f21c5ffd11d86.jpeg",
"zoomable": true
},
{
"id": "D24D52B21E05480C98AC462D39C73930",
"url": "https://i5.walmartimages.com/asr/7edefcf7-a034-43ce-bb8b-310a6eac75ce.9db12adf0465382afce69d51fa1966c5.jpeg",
"zoomable": true
},
{
"id": "3679FA1C13414910857B3F285F067D16",
"url": "https://i5.walmartimages.com/asr/c5992d42-c0b1-4f23-95b1-f47f82f50604.24221ec21fcd6f9f41d81983052b173e.jpeg",
"zoomable": true
}
],
"thumbnailUrl": "https://i5.walmartimages.com/asr/b6e643cb-03ca-428f-9b74-5b23c3f9b993.ccedb091549bc1473c5f21c5ffd11d86.jpeg"
},
"location": {
"postalCode": "95829",
"stateOrProvinceCode": "CA",
"city": "Sacramento",
"storeIds": [
"3081"
],
"addressId": null,
"intent": "SHIPPING",
"mpPickupLocation": null,
"pickupLocation": {
"storeId": "3081",
"accessPointId": null,
"accessType": null
}
},
"manufacturerName": "Pepperidge Farm, Inc",
"name": "Pepperidge Farm Goldfish Crackers Colors Cheddar, 30 oz. Carton",
"personalizable": false,
"numberOfReviews": 2629,
"orderMinLimit": 1,
"orderLimit": 20,
"offerId": "36AAE28DF80548DD95733C548D8E3F0A",
"offerType": "ONLINE_AND_STORE",
"priceInfo": {
"currentPrice": {
"price": 8.88,
"priceString": "$8.88",
"variantPriceString": "$8.88",
"currencyUnit": "USD",
"bestValue": null,
"priceDisplay": "$8.88"
},
"wasPrice": null,
"comparisonPrice": null,
"unitPrice": {
"price": 0.296,
"priceString": "29.6 ¢/oz",
"variantPriceString": null,
"currencyUnit": "USD",
"bestValue": null
},
"savings": null,
"shipPrice": null
},
"returnPolicy": {
"returnable": true,
"freeReturns": true,
"returnWindow": {
"value": 90,
"unitType": "Day"
},
"returnPolicyText": "Free 90-day returns"
},
"sellerId": "F55CDC31AB754BB68FE0B39041159D63",
"sellerName": "Walmart.com",
"sellerDisplayName": "Walmart.com",
"secondaryOfferPrice": {
"currentPrice": {
"priceType": null,
"priceString": "$23.15",
"price": 23.15
}
},
"shippingOption": {
"availabilityStatus": "AVAILABLE",
"slaTier": "ONE_DAY",
"deliveryDate": "2022-10-01T21:59:00.000Z",
},
"type": "Snack Crackers",
"pickupOption": {
"slaTier": "SAME_DAY",
"accessTypes": [
"PICKUP_INSTORE",
"PICKUP_CURBSIDE"
],
"availabilityStatus": "AVAILABLE",
},
"salesUnit": "EACH",
"usItemId": "16940090",
"upc": "014100096566",
"wfsEnabled": false,
"sellerType": "INTERNAL",
"ironbankCategory": "Food & Beverage"
},
"idml": {
"ingredients": {
"activeIngredients": null,
"inactiveIngredients": null,
"ingredients": {
"name": "Ingredients",
"value": "Made With Smiles And Enriched Wheat Flour (Flour, Niacin, Reduced Iron, Thiamine Mononitrate, Riboflavin, Folic Acid), Cheddar Cheese ([Cultured Milk, Salt, Enzymes], Annatto), Vegetable Oils (Canola, Sunflower And/Or Soybean), Salt, Contains 2% Or Less Of: Yeast, Sugar, Autolyzed Yeast Extract, Spices, Celery, Onion Powder, Monocalcium Phosphate, Baking Soda, Colors (Beet, Huito And Watermelon Juice Concentrates; Paprika And Turmeric Extracts).Contains: Wheat, Milk."
}
},
"longDescription": "<ul> <li>COLORFUL CHEESY GOLDFISH: Playful cheese crackers in a rainbow of colors, baked with a smile</li> <li>BAKED WITH REAL CHEESE: Always made with 100% real cheddar cheese and no artificial flavors or preservatives</li> <li>COLORS SOURCED FROM PLANTS: Pepperidge Farm uses colors sourced from plants - like red beet juice concentrate - to make Goldfish Colors colorful</li> <li>THE SNACK THAT SMILES BACK: Goldfish crackers have been making families smile for decades</li> <li>STOCK UP ON GOLDFISH CRACKERS: Large 30-oz. carton with easy-pour spout is the perfect size to portion out snacks for lunchboxes, gatherings and on-the-go treats</li> </ul>",
"shortDescription": "With Goldfish crackers, the smiles come naturally. Baked with 100% real cheddar cheese, plus no artificial flavors or preservatives, Goldfish Colors are a snack the whole family will adore. All colors are sourced from plants. The red Goldfish crackers are colored using a mix of beet juice concentrate and paprika extracted from sweet red peppers. Green comes from watermelon and huito juice concentrates mixed with extracted turmeric. The red-orange Goldfish are colored with paprika extracted from sweet red peppers, and finally, the orange Goldfish use annatto extracted from the seed of the achiote tree. With a large 30 oz. carton you can always come back for more, or have enough to feed a crowd. For Pepperidge Farm, baking is more than a job. It's a real passion. Each day, the Pepperidge Farm bakers take the time to make every cookie, pastry, cracker and loaf of bread the best way they know how by using carefully selected, quality ingredients.",
"interactiveProductVideo": null,
"specifications": [
{
"name": "Assembled Product Weight",
"value": "2.0964 POUNDS"
},
{
"name": "Food Form",
"value": "Crackers"
},
{
"name": "Brand",
"value": "Goldfish"
},
{
"name": "Assembled Product Dimensions (L x W x H)",
"value": "5.56 x 5.56 x 10.25 Inches"
}
],
"warnings": [
{
"name": "Warning Text",
"value": "Do not purchase if carton is open or torn."
}
],
"nutritionFacts": {
"calorieInfo": {
"name": "Calorie Information",
"mainNutrient": {
"name": "Calories",
"amount": "140",
"dvp": null,
"childNutrients": null
},
"childNutrients": null
},
"keyNutrients": {
"name": "Key Nutrients",
"values": [
{
"name": null,
"mainNutrient": {
"name": "Total Fat",
"amount": "5g",
"dvp": "6%",
"childNutrients": null
},
"childNutrients": [
{
"name": "Saturated Fat",
"amount": "1g",
"dvp": "5%",
"childNutrients": null
},
{
"name": "Trans Fat",
"amount": "0g",
"dvp": null,
"childNutrients": null
},
{
"name": "Polyunsaturated Fat",
"amount": "1.00g",
"dvp": null,
"childNutrients": null
},
{
"name": "Monounsaturated Fat",
"amount": "3.00g",
"dvp": null,
"childNutrients": null
}
]
},
{
"name": null,
"mainNutrient": {
"name": "Cholesterol",
"amount": "5mg",
"dvp": "2%",
"childNutrients": null
},
"childNutrients": null
},
{
"name": null,
"mainNutrient": {
"name": "Sodium",
"amount": "240mg",
"dvp": "10%",
"childNutrients": null
},
"childNutrients": null
},
{
"name": null,
"mainNutrient": {
"name": "Total Carbohydrate",
"amount": "20g",
"dvp": "7%",
"childNutrients": null
},
"childNutrients": [
{
"name": "Dietary Fiber",
"amount": "1g",
"dvp": "4%",
"childNutrients": null
},
{
"name": "Sugars",
"amount": "<1.00g",
"dvp": "0%",
"childNutrients": [
{
"name": "Includes Added Sugars",
"amount": "0g",
"dvp": null,
"childNutrients": null
}
]
}
]
},
{
"name": null,
"mainNutrient": {
"name": "Protein",
"amount": "3g",
"dvp": null,
"childNutrients": null
},
"childNutrients": null
}
]
},
"vitaminMinerals": {
"name": "Vitamins and Minerals",
"mainNutrient": null,
"childNutrients": [
{
"name": "Vitamin A",
"amount": null,
"dvp": "2%",
"childNutrients": null
},
{
"name": "Vitamin C",
"amount": null,
"dvp": "0%",
"childNutrients": null
},
{
"name": "Calcium",
"amount": "30mg",
"dvp": "2%",
"childNutrients": null
},
{
"name": "Potassium",
"amount": "50mg",
"dvp": "0%",
"childNutrients": null
},
{
"name": "Iron",
"amount": "1.2mg",
"dvp": "6%",
"childNutrients": null
},
{
"name": "Thiamin",
"amount": "0.15mg",
"dvp": "10%",
"childNutrients": null
},
{
"name": "Riboflavin",
"amount": "0.17mg",
"dvp": "15%",
"childNutrients": null
},
{
"name": "Niacin",
"amount": "2.3mg",
"dvp": "15%",
"childNutrients": null
},
{
"name": "Folic Acid",
"amount": "45.00mcg",
"dvp": null,
"childNutrients": null
}
]
},
"servingInfo": {
"name": "Serving Information",
"values": [
{
"name": "Servings Per Container",
"value": "28.0",
"attribute": null,
"values": null
},
{
"name": "Serving Size",
"value": "55 Pieces (30g)",
"attribute": null,
"values": null
}
]
},
},
"videos": [
{
"poster": "https://images.salsify.com/video/upload/s--SsJ7mRpe--/so_auto,c_limit,h_1000,w_1000/yszohpicwcbrwcdqn2jk.jpg",
"title": null,
"versions": {
"small": "https://images.salsify.com/video/upload/s--bEwAMd1i--/yszohpicwcbrwcdqn2jk.mp4",
"large": "https://images.salsify.com/video/upload/s--bEwAMd1i--/yszohpicwcbrwcdqn2jk.mp4"
}
}
],
"product360ImageContainer": null
},
"reviews": {
"averageOverallRating": 4.7318,
"aspects": [
{
"id": "9636",
"name": "Snack",
"score": 99,
"snippetCount": 436
},
{
"id": "56",
"name": "Taste",
"score": 95,
"snippetCount": 301
},
{
"id": "178",
"name": "Colors",
"score": 98,
"snippetCount": 214
},
{
"id": "407",
"name": "For Kids",
"score": 99,
"snippetCount": 90
},
{
"id": "48",
"name": "Price",
"score": 100,
"snippetCount": 59
},
{
"id": "4558",
"name": "Fish",
"score": 97,
"snippetCount": 18
}
],
"lookupId": "1K83G4N9GAM8",
"customerReviews": [
{
"rating": 5,
"reviewSubmissionTime": "3/9/2022",
"reviewText": "I absolutely loved this product. I would definitely recommend these to anyone looking for a nice little snack for themselves or their child.",
"reviewTitle": "I absolutely loved this",
"userNickname": "member50dab",
"photos": null,
"badges": null,
"clientResponses": null,
"syndicationSource": {
"logoImageUrl": "https://contentorigin.bazaarvoice.com/influenster/default/influenster.png",
"contentLink": null,
"name": "influenster.com"
}
},
{
"rating": 1,
"reviewSubmissionTime": "11/4/2021",
"reviewText": "Smashed",
"reviewTitle": "Smashed",
"userNickname": "sean",
"photos": null,
"badges": [
{
"badgeType": "Custom",
"id": "VerifiedPurchaser",
"contentType": "REVIEW",
"glassBadge": {
"id": "VerifiedPurchaser",
"text": "Verified Purchaser"
}
}
],
"clientResponses": null,
"syndicationSource": null
}
],
"ratingValueFiveCount": 2134,
"ratingValueFourCount": 349,
"ratingValueOneCount": 18,
"ratingValueThreeCount": 100,
"ratingValueTwoCount": 28,
"roundedAverageOverallRating": 4.7,
"topNegativeReview": {
"reviewId": "271252006",
"rating": 1,
"reviewSubmissionTime": "11/4/2021",
"userNickname": "sean",
"negativeFeedback": 0,
"positiveFeedback": 0,
"reviewText": "Smashed",
"reviewTitle": "Smashed",
"badges": [
{
"badgeType": "Custom",
"id": "VerifiedPurchaser",
"contentType": "REVIEW",
"glassBadge": {
"id": "VerifiedPurchaser",
"text": "Verified Purchaser"
}
}
],
"clientResponses": null,
"syndicationSource": null
},
"topPositiveReview": {
"reviewId": "203653674",
"rating": 5,
"reviewSubmissionTime": "3/9/2022",
"userNickname": "member50dab",
"negativeFeedback": 0,
"positiveFeedback": 0,
"reviewText": "I absolutely loved this product,they are a great little snack for movies,late night,on the go,great for toddlers.they taste so good,very cheesey which I loved (I love cheese).I would definitely recommend these to anyone looking for a nice little snack for themselves or their child.",
"reviewTitle": "I absolutely loved this",
"badges": null,
"syndicationSource": {
"logoImageUrl": "https://contentorigin.bazaarvoice.com/influenster/default/influenster.png",
"contentLink": null,
"name": "influenster.com"
},
"clientResponses": null
},
"totalReviewCount": 2629
}
}
}
Data exploration
Let's now parse relevant data from downloaded product detail JSON files and load it into pandas data frame for analysis. We'll extract the following fields:
- product ID
- name
- rating
- price
- main category and sub-categories
- nutrients:
- fat
- protein
- total carbohydrate
- sugars
- other carbohydrates
- cholesterol
Data cleaning
Raw scraped data contained many missing values, errors, outliers etc. It required some filtering, a few transformations and aggregations to be useful. The most important data cleaning 🧹 steps:
- remove columns with all missing values
- remove product with all nutrients missing
- fill missing nutrient values with 0s
- exclude products with main category other than food
- exclude sub-categories having 10 products or fewer
- aggregate different nutrient types:
- fat: combine (sum) saturated, trans, polyunsaturated, monounsaturated fats and take maximum with total fat
- sugars: take maximum of sugars and added sugars and combine (add) sugar alcohol
- other carbohydrates: combine (sum) other carbohydrates with all types of fiber (dietary, soluble, insoluble)
- exclude products having more than 1 kg of protein, sugar, or fat per serving as outliers
- exclude products having all nutrients set to 0
- compute main nutrient as having maximum weight per serving among cholesterol, fat, protein, sugar, and other carbohydrates
After applying all the transformations and filters, we are left with 15,502 products with their nutrient data.
Data exploration python notebook implementing all the steps is available in GitHub repository.
Categories
To get an overview of the data, we will start by looking at the number of products per category:
Main nutrient
Let's now see what is the number of products per main nutrient:
Based on the values from the chart above, for 46.1% of all considered products (7,152/15,502) sugar is the main nutrient 😮. This could be because of Snacks, Cookies & Chips and Candy categories since together they have over 7,500 products (almost 50%). In this case, let's exclude them and look at the distribution of main nutrients:
Surprisingly, the share of products having sugar as the main nutrient is even higher now and it's 49.5% 🤯. Let's remember that in our dataset sugars include added sugars and sugar alcohol but we also combined all types of fat into one nutrient for simplicity.
Rating vs sugar
Does having sugar as the main nutrient have any effect on product rating❓
To find out, we will use a subset of the data comprising products having rating information (79%). Let's divide products into bins by rating and check for the share of products with sugar as the main nutrient.
There seems to be a trend, however, let's check how it looks for fat and protein.
For fat and protein the trend seems to be reversed. It looks like food producers figured out which ingredient is the key to make a product more compelling to customers.
Limitation
This analysis is meant to show how you can obtain useful information by web scraping Walmart product data. Let's remember that correlation does not prove causation.
There are potentially many reasons for this dataset to be biased. The total number of products that we scraped was over 70,000 yet for most of them there either was no nutrition facts data available or it was only included in the product images and it would require OCR to identify it. Obtaining this additional data might significantly affect the results.
Conclusion
What is the share of products having sugar as the main nutrient❓
It's almost 50% 🤯 for our dataset of products scraped from Walmart.
Is there any relation between product rating and its nutrients ❓
In our dataset, products having sugar as the main nutrient tend to have higher rating 📈.
As you can see, it is really easy to scrape publicly available product data from Walmart using Scraping Fish API. In a similar way, you can scrape product details from other categories as well as other websites that contain relevant information for you or your business.
Let's talk about your use case 💼
Feel free to reach out using our contact form. We can assist you in integrating Scraping Fish API into your existing web scraping workflow or help you set up a scraping system for your use case.