Scraping Airbnb


Scraping Airbnb

San Francisco Bay Area, due to it's tech business importance as well as numerous iconic landmarks is a common destination for Airbnb guests. Have you ever wondered how does the hosting landscape look like there? What is the price for a stay you should expect to pay (or charge as a host)? These questions can be answered using web scraping and basic data analysis skills. We will show you how to effortlessly scrape Airbnb even though it's using JavaScript to render its content and showcase some basic data exploration.
It's important to point out that we are scraping Airbnb as of May 2022. If Airbnb changes something on their website that we rely on, the code in this post may no longer work and will have to be adjusted. If you experience any problem, feel free to open an issue on GitHub and we will investigate it.
How to get the data? Web scraping to the rescue!
To the best of our knowledge, Airbnb by itself doesn't publish its offers in an easily digestible form (e.g. a csv file or an API). However, Airbnb is a publicly available website and you can query and browse offers without logging in. With the help of Scraping Fish API you don't need to be an expert in web scraping to easily get the data about Bay Area's Airbnb apartments and use it to gain the desired insights.
Rendering JavaScript
Airbnb doesn't work without JavaScript rendering. You can try accessing it with JavaScript disabled in your browser - there's no data. That means traditional plain HTTP based web scraping (e.g. just using requests + BeautifulSoup combo in python) won't cut the mustard here - we need a way to render the JavaScript. We will use our Scraping Fish API which comes with JS rendering included. Here's how it works: instead of directly trying to access Airbnb's website we'll pass it through Scraping Fish API and it'll handle all the hussle for us (render the JS in this case). All we need is prefixing the urls as you'll see in the following snippet:
API_KEY = "your API key"
# don't forget to set render_js=true - it won't work without it
url_prefix = f"https://api.scrapingfish.com/api/v1/?render_js=true&api_key={API_KEY}&url="
If you want to try running the code by yourself, you'll need a Scraping Fish API key. You can buy the smallest pack for just $2.
Scraping and data extraction
When preparing a query, there are two important things to note:
- For any query, Airbnb lists 300 offers which are not all available offers.
- Price is only displayed when a stay date range is specified and certain apartments may not be available on these dates.
Therefore, to get a good representation of available offers we will scrape data from different days. Ideally, we'd ask for all the dates but to keep the processing time short we'll constrain ourselves to days between 2022-06-01 and 2022-10-14 and sample with 45 days frequency, i.e. 4 days: 2022-06-01, 2022-07-16, 2022-08-30, 2022-10-14. You can set the range and frequency however you wish but keep in mind that it may take a very long time to get densely sampled data and there's a diminishing returns effect when it comes to improving the results.
Summing up, the idea is to start from some date, increase it by set frequency after each iteration, during the iteration query Airbnb using the single day stay date range, traverse the 15 pages of results (totalling 300 offers) per day, extract the information about the offers and append it to the collection. Here's the high level overview (we will fill in the undefined functions later, you can get the full code in a jupyter notebook form here).
Here are the parameters used for getting the data, i.e. the query and most importantly date range and sampling frequency:
query = "San-Francisco-Bay-Area--CA--United-States"
start_date = datetime.date(2022, 6, 1)
end_date = datetime.date(2022, 10, 14)
freq = '45D'
num_guests = 1
At a high level the extracting is as simple as that:
offers = []
for date in tqdm(pd.date_range(start_date, end_date, freq=freq)):
offers += process_date(checkin_date=date)
For each date we need to scrape all the 15 pages of offers (20 per page). The URL template for it is
https://www.airbnb.com/s/{query}/homes?checkin={checkin}&checkout={checkout}&adults={num_guests}&items_offset={items_offset}&display_currency=USD
where:
query- in our case it's"San-Francisco-Bay-Area--CA--United-States",checkin- check in date inYYYY-MM-DDformat,checkout- check out date - in our case it's always check in + 1 day,num_guests- number of guests we want to accomodate - always 1 in our case to get as much aparatments as possible,items_offset- offset for the paging mechanism, equal to(page - 1) * 20.
def process_date(checkin_date, num_guests=1):
checkin = checkin_date.strftime("%Y-%m-%d")
checkout = (checkin_date + datetime.timedelta(days=1)).strftime("%Y-%m-%d")
offers = []
total_num_pages = 15
page = 1
end = False
while page <= total_num_pages:
items_offset = (page - 1) * 20
url = f"https://www.airbnb.com/s/{query}/homes?checkin={checkin}&checkout={checkout}&adults={num_guests}&items_offset={items_offset}&display_currency=USD"
url = quote_plus(url)
response = requests.get(f"{url_prefix}{url}")
soup = BeautifulSoup(response.content, "html.parser")
try:
offers_divs = soup.select("div.cm4lcvy")
for offer in offers_divs:
current_offer = parse_offer(offer, checkin)
if current_offer is not None:
offers.append(current_offer)
page += 1
except Exception as e:
with open(f"{items_offset}.html", "wb") as f:
f.write(response.content)
raise e
return offers
The offers = soup.select("div.cm4lcvy") may seem mysterious to you. It extracts all the HTML elements containing info about offers using a CSS selector (basically, it means get all the divs with "cm4lcvy" class). We've got the class name here by inspecting the relevant element in web browser developer tools. These elements will then be used in the parse_offer function to extract all the info we need. We'll store:
- offer's id,
- price for a given day,
- check in day,
- type (a room, whole place etc.),
- capacity (max. number of guests),
- number of bedrooms, number of beds,
- number of bathrooms,
- whether it has a wi-fi,
- kitchen,
- washer,
- free parking.
We'll only use limited part of those values in this post. The next function extracts and parses the data. We also map singular and plular forms to get a single value for number of bathrooms/bedrooms/beds by using key_map dictionary (you can check it in the accompanying code):
def parse_offer(offer, checkin):
offer_id = offer.select("a")[0]['target'].split("listing_")[-1]
offer_price = float(''.join(offer.select("span._tyxjp1")[0].text.replace(",", "").split("$")[1:]))
offer_type = offer.select("div.mj1p6c8")[0].text.split(" in")[0]
offer_features = [feature.text for feature in offer.select("span.mp2hv9t")]
current_offer = {
"id": offer_id,
"price": offer_price,
"checkin": checkin,
"type": offer_type,
}
feature_sets = offer.select("div.i1wgresd")
basic_features = [t.text.lower() for t in feature_sets[0].select("span.mp2hv9t")]
other_features = [t.text.lower() for t in feature_sets[1].select("span.mp2hv9t")] if len(feature_sets) > 1 else []
skip = False
for feature in basic_features:
split = feature.split()
if len(split) > 1:
key = ' '.join(split[1:])
if key == 'room types':
return None
current_offer[key_map[key]] = split[0]
else:
if split[0].lower() == 'studio':
current_offer['bedrooms'] = 0
current_offer['wi-fi'] = 'wifi' in other_features
current_offer['kitchen'] = 'kitchen' in other_features
current_offer['washer'] = 'washer' in other_features
current_offer['free parking'] = 'free parking' in other_features
return current_offer
All right, we've got the precious data now and we are ready to gain the interesting stuff out of it!
Basic data exploration
Now that we have the data ready in memory, let's create a pandas dataframe and explore it. We will also write our data to csv and load it which has an additional benefit of auto-conversion of numeric data to proper types.
offers_df = pd.DataFrame(offers)
offers_df.to_csv('./data.csv', sep=';', index=False)
offers_df = pd.read_csv("./data.csv", sep=";")
Data cleaning
We will clear duplicated ads first, count the data and count values by type.
offers_df = offers_df.drop_duplicates(subset=['id'], keep='last')
print("Number of data points:", len(offers_df))
print(offers_df['type'].value_counts())
This gives us:
| Number of data points | 677 |
|---------------------------|-----|
| Private room | 241 |
| Entire home | 104 |
| Entire guest suite | 96 |
| Entire guesthouse | 75 |
| Entire rental unit | 43 |
| Room | 20 |
| Entire cottage | 14 |
| Hotel room | 13 |
| Entire condo | 8 |
| Entire cabin | 7 |
| Tiny home | 6 |
| Entire bungalow | 6 |
| Entire apartment | 5 |
| Hostel beds | 5 |
| Hostel room | 4 |
| Entire vacation home | 4 |
| Treehouse | 4 |
| Farm stay | 3 |
| Tent | 3 |
| Shared room | 2 |
| Entire villa | 2 |
| Boat | 2 |
| Houseboat | 2 |
| Yurt | 2 |
| Entire serviced apartment | 1 |
| Entire loft | 1 |
| Tower | 1 |
| Camper/RV | 1 |
| Entire townhouse | 1 |
| Bus | 1 |
Here we see a fair count of detailed types but we are more insterested in broader type, i.e. we want only to count: "Entire place", "Private room", "Hotel room" and "Shared room" using offers_df["type"].replace({...}) (you can see it in the code).
What types of offers are the most common? How many beds are expected per type?
Now, let's see how many offers of those broader types are there and at the same type find out how many beds those types typically offer:
plt.figure(figsize=(14,8))
ax = sns.histplot(data=offers_df, x="type", shrink=0.9, alpha=0.9, multiple="stack", hue="beds")
for label in ax.get_xticklabels():
label.set_rotation(35)
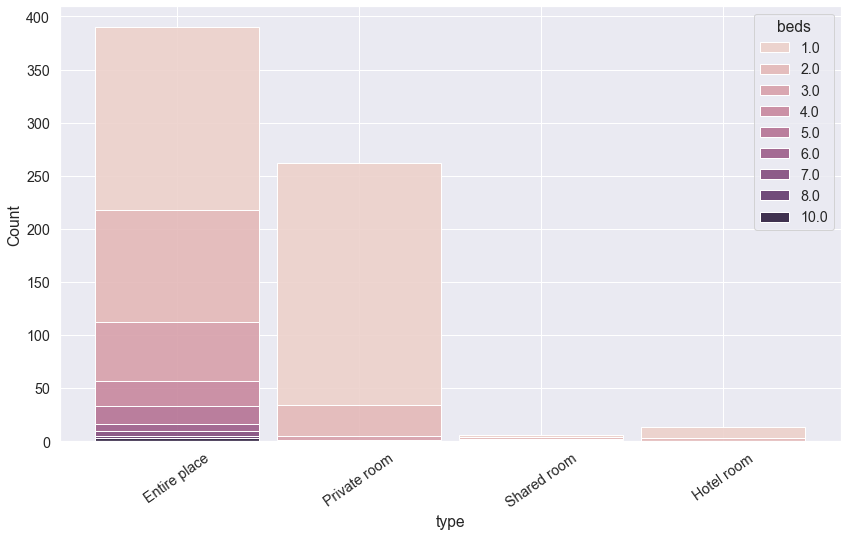
Entire places clearly dominate the space and most of the places have 1 or 2 beds. Let's now see how prices relate to capacity of the offers:
Price to max. number of guests and most expensives offers
We will now check how prices relate to guest capacity.
plt.figure(figsize=(14,8))
ax = sns.stripplot(data=offers_df, x="capacity", y="price", dodge=True, hue="type")
ax.set(xlabel="Max. number of guests", ylabel="Price")
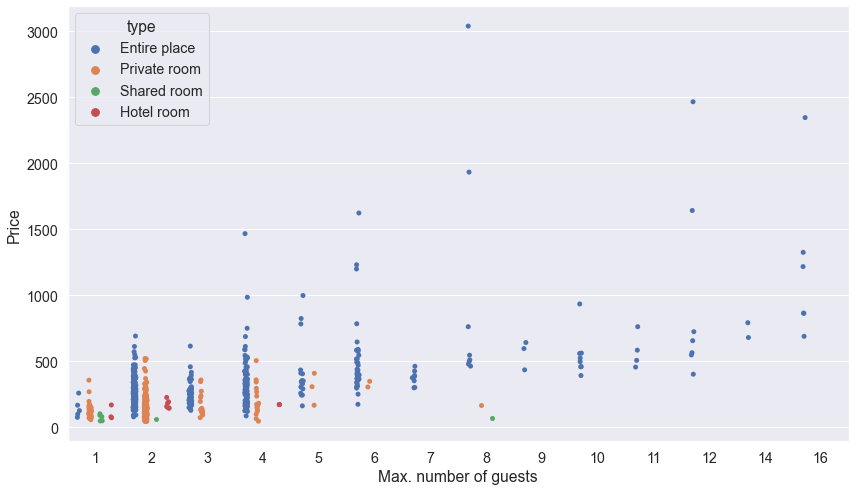
What about the most expensive offers? Here's the list of those priced for over $1,500:
Wrap up
Airbnb is an example website which doesn't show much content without javascript enabled. Scraping Fish javascript rendering feature made dealing with this a breeze.
We barely scratched the surface of what's possible when it comes to data exploration. For the sake of simplicity we restricted our analysis to relatively small dataset. However, we plan to get much more data and conduct a more thorough analysis so stay tuned, follow us on 𝕏 and check our blog for more!
Want to try Scraping Fish API?
If you are interested in scraping data and building products around it give Scraping Fish a try. You can start with only $2 and absolutely no commitment.